

- ご利用事例
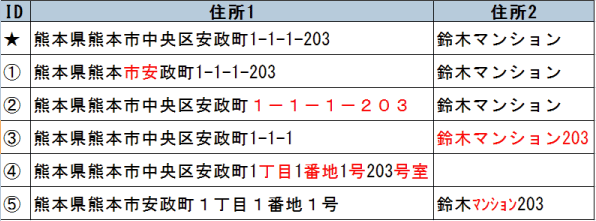
突然ですが、上記の住所は実は全部同一だという事がおわかりになりますでしょうか?
★のついているデータと比較していくと、①は住所に「中央区」が入っていません。
熊本市は2012年に政令指定都市となったため、4つの区に区分けがされました。
2012年以前の住所データでは区分けされる前のデータですので、
①のように区の名前が入っていないデータがあります。
このような区が入っていない郵便物でも、ポストに投函すれば郵便局できちんと該当住所が判別され、
届ける事が出来るので、一見問題が無いかと思われがちですが、そこには大きな問題があります。
もし、このデータファイルを使ってDMを出したいと考えているとした場合
「同じ宛先には重複して送らないようにして、なるべく費用を抑えたい」とお考えになるかと思います。
ですが、★と①は同じ場所を指しているものの、
データの形が違うため、機械的に「同じもの」として認識する事ができません。
そのため、このままこのデータを使用してしまうと、ムダに同じ宛先にDMを送ってしまう事になります。
2017年より、郵便葉書の料金が「52円」から「62円」に大幅値上げされた為、
仮に1万枚DMを送ろうとした場合52万円の経費がかかります。
ここにもし、重複した無駄なデータが大量に入っていて、
もし発送されるDMが2万枚になってしまった場合、
104万円もの費用が発生し、50万円以上ムダな経費が発生する事になります。
もちろん、経費としてもムダになりますが、受け取った方からすると、「なぜ同じ物が2枚も???」
という印象を与えてしまい、せっかくのDMの効果が薄れてしまうと思われます。
そういった事が無いように、住所データのクリーニング作業(クレンジング)が非常に重要なものになってきます。
それを踏まえて上の表の②の事例をみていきましょう。

★と比較すると、「数字」と「ハイフン」が全角になっています。
このようなデータも機械的には同じ物と見なされません。
データクリーニングして半角に整える事によって、重複として判定されるようになります。
③の場合はどうでしょうか。

ここでは、マンションの号室が住所2のセルに入っているため、同一と見なされません。
これもあらかじめ号室は住所1の末尾にいれるのか、またはマンション名の後に入れるのかを決めた上で
住所データクリーニング作業を行えば、重複として見なされます。
④もみていきましょう。

こちらについては、丁目や番地の区切りがハイフンではなく、文言がそのまま入っています。
こういったものも仕様をあわせてハイフンにすれば重複として見なされます。
⑤はどうなっているでしょうか。

については、マンション名が半角カナになっています。
②で数字やハイフンが全角になっている事例を見ましたが、
カタカナについても同種にしておかないと重複と見なされません。
シブリュでは数字、英語、カタカナの全半角についても統一処理をする事が可能です。
今回あげたものは一例です。
もちろん①から⑤のズレが全て混合したようなデータも御座います。
そういったものもシブリュでは可能な限り統一することにより、
ムダなデータを減らし、正確な住所データに仕上げる事が可能です。
コスト削減、DMのPR効果向上などにシブリュの住所データクリーニング作業を一度ご検討下さいませ。